GPT-5.2-Codex vs Claude Opus 4.5 vs Gemini Pro: Which Model Actually Codes Best?

The internet cannot agree on which AI model codes best.
- @themandalorenzo says "Opus 4.5 is KING!" for coding.
- @CosmicSenate says Codex is smarter and Opus is "quite weak" for hard problems.
- @VictorTaelin says Opus is "a bit dumber than Gemini but way more usable."
So I ran three identical tasks on GPT-5.2-Codex, Claude Opus 4.5, and Gemini Pro. The results surprised me. Opus uncovered insights in data analysis that the other models missed. Codex was the only model to write tests without prompting. Gemini was fastest, but its conclusions did not match the data.
Here is what actually happened.
What I Tested
The environment:
- VS Code 1.108
- GitHub Copilot Pro with agent mode enabled
- Same prompt structure for each model
- Fresh chat for each test (no context carryover)
The Workflow:
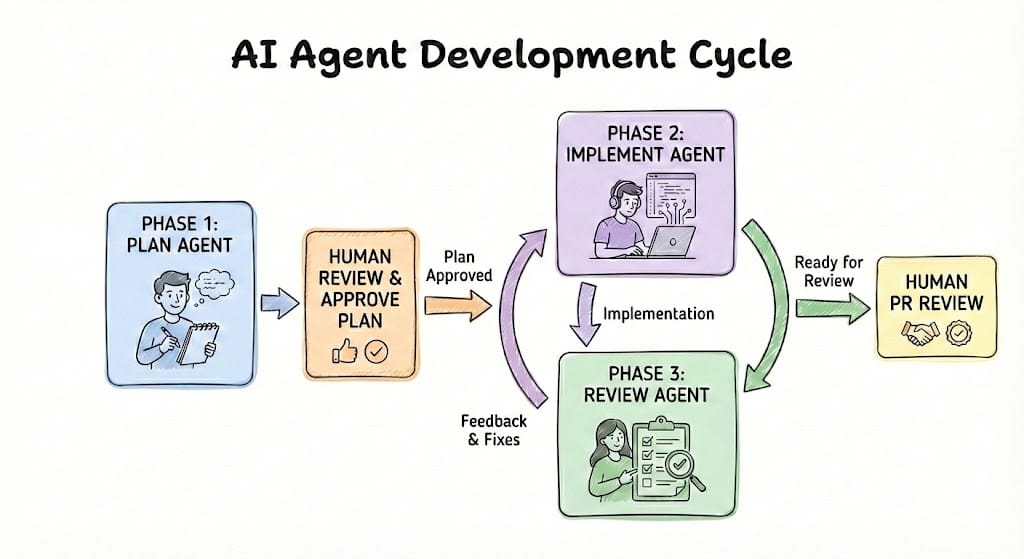
Three phases per task:
- Plan Agent: Gave each model my base prompt. I answered questions until the plan was ready.
- Implement Agent: Read the plan and implemented it.
- Review Agent: Compared implementation to plan, reviewed code, passed back for fixes until ready for human review.
The Tasks:
- Refactoring Task: Extract a messy, vibe coded repo into a clean Python package with a pipeline for generating, deduplicating, and scoring ideas.
- Feature Implementation Task: Add Flask API endpoints to the Idea Generation Repo so I could deploy it and call a web endpoint to get ideas back.
- Data Analysis Task: Analyse UK road safety data in a Jupyter notebook. Answer questions about accident patterns.
The Results
Refactoring
I had a messy, vibe coded repo. The goal: extract it into a clean Python package with a proper pipeline.
| Aspect | Opus 4.5 | Codex | Gemini Pro |
|---|---|---|---|
| Duration | 29 min | 19 min (fastest) | 26 min |
| Plan detail | 26 items | 12 items | Minimal |
| Test coverage | Comprehensive | Smoke test only | Basic script |
| Documentation | Comprehensive | Brief | Minimal |
What I noticed:
Codex was fastest, which contradicted the online consensus. It stayed focused: simple plan, bare minimum implementation, plus a smoke test.
Gemini did the bare minimum but took longer to gather context. Its planning questions were uninspiring.
Opus took the longest, but delivered the most. It went above and beyond: proper test suite, comprehensive documentation, and it fixed TODOs I had left in the code. Codex and Gemini ignored them.
Verdict: Opus. It delivered a package I could ship without significant rework. Codex would need tidying. Gemini would need substantial
Feature Implementation
I took the Opus version from the previous task and added Flask endpoints: /pipeline, /generate, and /health.
| Aspect | Opus 4.5 | Codex | Gemini Pro |
|---|---|---|---|
| Duration | 8 min | 11 min (slowest) | 9 min |
| Tests written | None | Yes (8 tests) | None |
| Error handling | Good | Good | Basic |
| Documentation | Most thorough | Good | Adequate |
| Production ready | Good | Best | Functional |
What I noticed:
Codex was the only model to write tests without being asked. Opus had good error handling and thorough documentation, but no tests. Gemini was basic.
Verdict: Codex. It was the most production ready with tests without prompting. Opus was close but lacked tests. Gemini got the job done but nothing more.
Data Analysis
I took UK road safety data and asked each model to answer four questions (full task prompt on GitHub):
- When do severe accidents spike, and is it driven more by time of day or road type?
- Which combinations of weather, light conditions, and road surface correlate with the highest severity?
- Are older vehicles or certain vehicle types over represented in severe accidents once normalised by volume?
- Do urban and rural areas show different severity patterns at the same speed limits?
| Aspect | Opus 4.5 | Codex | Gemini Pro |
|---|---|---|---|
| Duration | 22 min | 33 min (slowest) | 11 min (fastest) |
| Data cleaning | Thorough | Basic | Basic |
| Insight depth | Best | Adequate | Surface level |
| Graph quality | Good | Basic, harder to read | Good, readable |
| Conclusions | Data backed | Basic | Seemed to bluff |
What I noticed:
Opus struggled with VS Code notebook tools; I had to help it run cells. Despite that, it delivered the best results. It wrote explanatory text that showed it understood the data.
Gemini was fastest, but bluffed its conclusions; it claimed rush hours were most dangerous when the data showed late night was worse. Codex was slow but accurate.

Opus used bar charts; Gemini used line charts. The bar chart makes the trend obvious: rural areas are more dangerous than urban for certain speed buckets. Gemini's line chart is harder to read, and its data cleaning left outliers around 10 mph.
Verdict: Opus by a wide margin. It explored the data properly and drew conclusions I could trust. You can see all three notebooks on GitHub: Opus, Codex, Gemini.
The Final Verdict
| Criterion | GPT-5.2-Codex | Claude Opus 4.5 | Gemini Pro |
|---|---|---|---|
| SWE-bench | 71.8% | 74.4% | 74.2% |
| Best for | Production ready code, test suites | Complex apps, meticulous planning | Speed, simple implementations |
| Feature implementation | Best tests | Most documentation | Simplest code |
| Data analysis | Basic, slow | Deep insights | Fast but generic |
| Refactoring | Fastest, minimal polish | Ready to ship | Basic |
| Relative speed | Slowest | Middle | Fastest |
The personality test:
Codex is the engineer focused on getting the job done with good production code and tests, then stops there.
Opus is the overachiever who creates detailed plans and may go a bit over scope, but delivers quality work. You might need to steer it to stay focused.
Gemini does what you ask and no more, but lacks the polish Codex has. It got the job done on feature implementation and refactoring, but bluffed the data analysis.
When to Use What
Codex: Production ready code with tests without prompting. Best for well defined tasks where you do not want the model to add more scope. Skip it for data analysis.
Opus: Best all rounder. Detailed plans, comprehensive documentation, goes slightly beyond what you ask, but I like that. Data analysis was impressive. Does not work well with VS Code notebook tools, but the results are worth the workaround.
Gemini: Speed when good enough is good enough. Simple implementations, massive context window. But the output needs review; do not trust it for analysis work.
My recommendation:
- Default to Opus for most work
- Use Codex for smaller, well defined tasks
- Skip Gemini unless speed is your only concern
On budget: Use Codex over Opus unless you are doing data analysis work.
The Bigger Point
The difference between Codex and Opus was not as big as I expected.
They were pretty close across the tasks. Opus won the refactoring and data analysis; Codex won the feature implementation. I think context engineering would get both of them to perform well consistently.
My advice: pick a model and stick with it. Learn its weaknesses and update your instructions. Opus is best by default, but Codex is cheaper, and with effort you could get it to Opus level. Gemini is not worth your time.
You can see this in the test results: Opus wrote comprehensive tests for Task 1 but none for Task 2. Codex did the opposite. Stronger custom instructions around testing would get both models to align more consistently. It is an iterative process.
A well-written instruction file improves every model. I will share how I set mine up in a future post.
Conclusion
Opus 4.5 has my money. Detailed plans, faithful execution, goes beyond what you ask (in a good way). The data analysis was surprisingly good.
Codex for well defined tasks. Production ready code with tests without prompting. Does what you ask and stops. I would use this next.
I would not use Gemini Pro. Consistently basic. Fast, but needs significant review.
This comparison is dated January 2026. I will update it when models change significantly.
Want updates when I re-run these tests?
I will be updating this comparison whenever a major model release drops. Subscribe to get notified or follow me on X @jackcreates_ for quicker takes.
Appendix
What Others Say
| Aspect | GPT-5.2-Codex | Claude Opus 4.5 | Gemini Pro |
|---|---|---|---|
| Speed | Slow; minutes of "thinking" before output | Fast iterations | 4x faster than Codex |
| Best for | Notebooks, spreadsheets, structured deliverables | Refactoring, debugging, CLI workflows | UI/UX, rapid prototyping, massive context |
| Weaknesses | Latency, struggles with UI and animations | Context limits, cost, can be "lazy" | Hallucinations, forgets context in long chats |
| Working with it | Reads silently, then delivers polished output | Stubborn about best practices, surgical | Confident but sometimes invents APIs |
Sources: @MohitKaleAI, @slow_developer, @TheAhmadOsman, @dejavucoder, @mitsuhiko, @cheatyyyy
Video sources: Combinator Table Creation (Code Report), Ultimate AI Showdown (Dom the AI Tutor), Claude Code Guide (Alex Finn)
Model Specs
| Spec | GPT-5.2-Codex | Claude Opus 4.5 | Gemini Pro |
|---|---|---|---|
| Released | December 18, 2025 | November 24, 2025 | November 18, 2025 |
| Price (input/output per 1M tokens) | $1.75 / $14.00 | $5.00 / $25.00 | $2.00 / $12.00 |
| Context window | 400K | 200K (1M beta) | 1M |
| Max output | 128K | 64K | 65K |
| Tokens per second* | 40 to 56 tps (chat version only) | 37 to 50 tps | 45 to 86 tps |
*Tokens per second from OpenRouter. GPT-5.2-Codex was not listed at time of writing.
